Bustub’s extendible hash tables (CMU-15445)
Welcome to my take on the implementation of extendible hash tables (minus the code btw, owning to the educational policies)
Motivation
I have been recently getting my hands dirty with C++ internal semantics and the implementation of different kinds of database internals and “the learning curve is steep” is an understatement, exhibit A—
In this post, I will be discussing the implementation (overview) of the Bustub extendible hashtable index insertions. For some context, CMU-15445 is an excellent course that stands out for its comprehensive approach to database systems. Its unique blend of theoretical foundations and practical applications provides students with a solid understanding of the intricacies involved in managing and building data stores.
Personally, this is my second attempt at this course, and making some headway has been amazing. For this post, we’ll be discussing Project 2 (Hash Index), building our own hash index using extendible hash tables!
I tried my best to figure out a good source to discuss this particular assignment but there didn’t seem to be a lot many articles in English. A few notable ones that I came across were :
- https://jameywoo.github.io/post/cmu15-445/project2-extendible-hash-index/#task-2---hash-table-implementation
- https://auzdora.github.io/2023/03/22/Extendible_Hash_Table/
Eh, so what’s hashing?
For the uninitiated, a hashtable in simplest terms is a key value store data structure in which, before inserting a key, you’d hash it (which will decide in which bucket will this key land) and store it. Primarily, you’d have three simple operations for the hash table which are:
- Insert(key, value)
- Delete(key)
- Get(key)
As you can think, there might be multiple approaches to achieve this, we can broadly categorize them into a couple of sections static and dynamic hash tables.
Static Hash Tables
The general theme of these hashtables is that they will have a fixed number of slots and differ in the way they handle collisions and deletions.
Some of the techniques are
Linear Probing
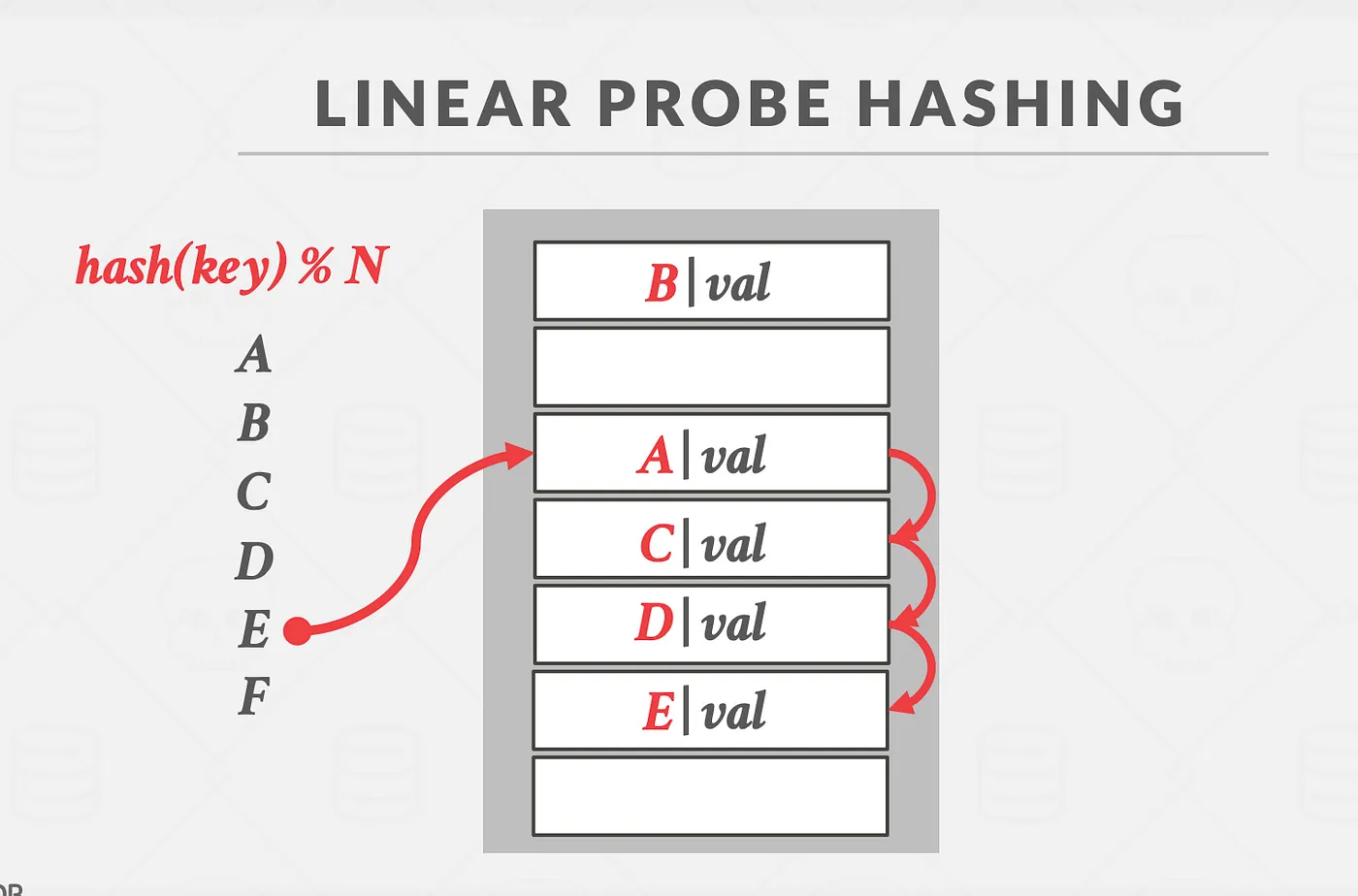
- Inserts: Hashes the key to an index and if the slot is already full, moves on to the next one linearly and loops around if reaches the end of the array.
- Deletes: You can put tombstones on the slots after deletion, this will be treated as an open slot during insertion and will be ignored during key lookup.
Robin Hood Hashing
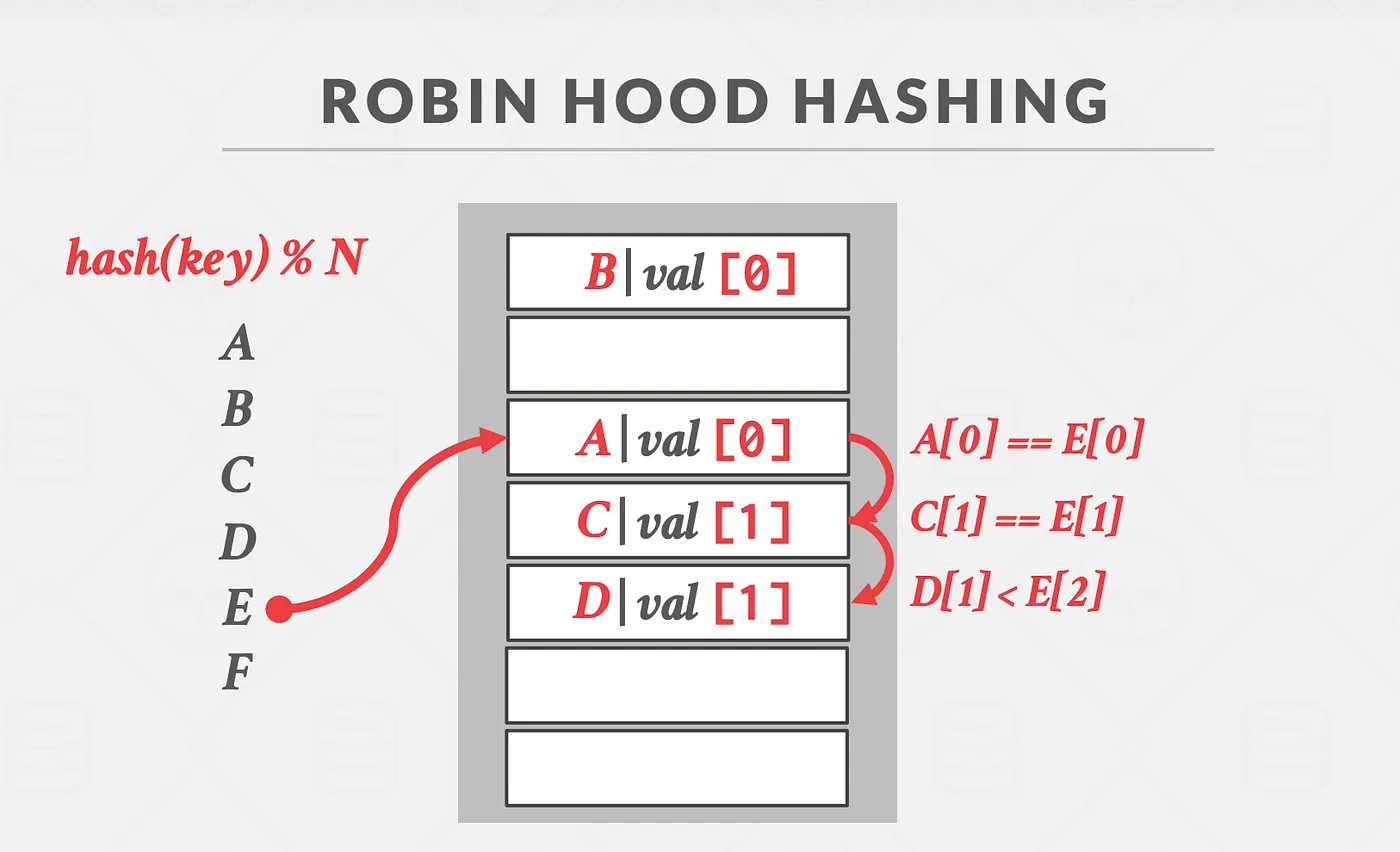
- Inserts: The insertion here is a bit weird… If the hashed slot is free, we’ll insert the key right here. But if it isn’t, we’ll linearly go down and pick the first slot according to:
1. Is the slot free? If yes just put the new key there and also store how far was it from the original index.
2. If not, then check if the current key is farther from its hashed slot. If not, then this new key will take its place and the old key will be pushed further.
Dynamic Hash Tables
The theme here is that we can increase and decrease the overall size of the hashtables according to a fixed set of constraints, ideally, you can fit any number of keys if you let the data structure grow further enough without complete key reallocation.
Chained Hashing
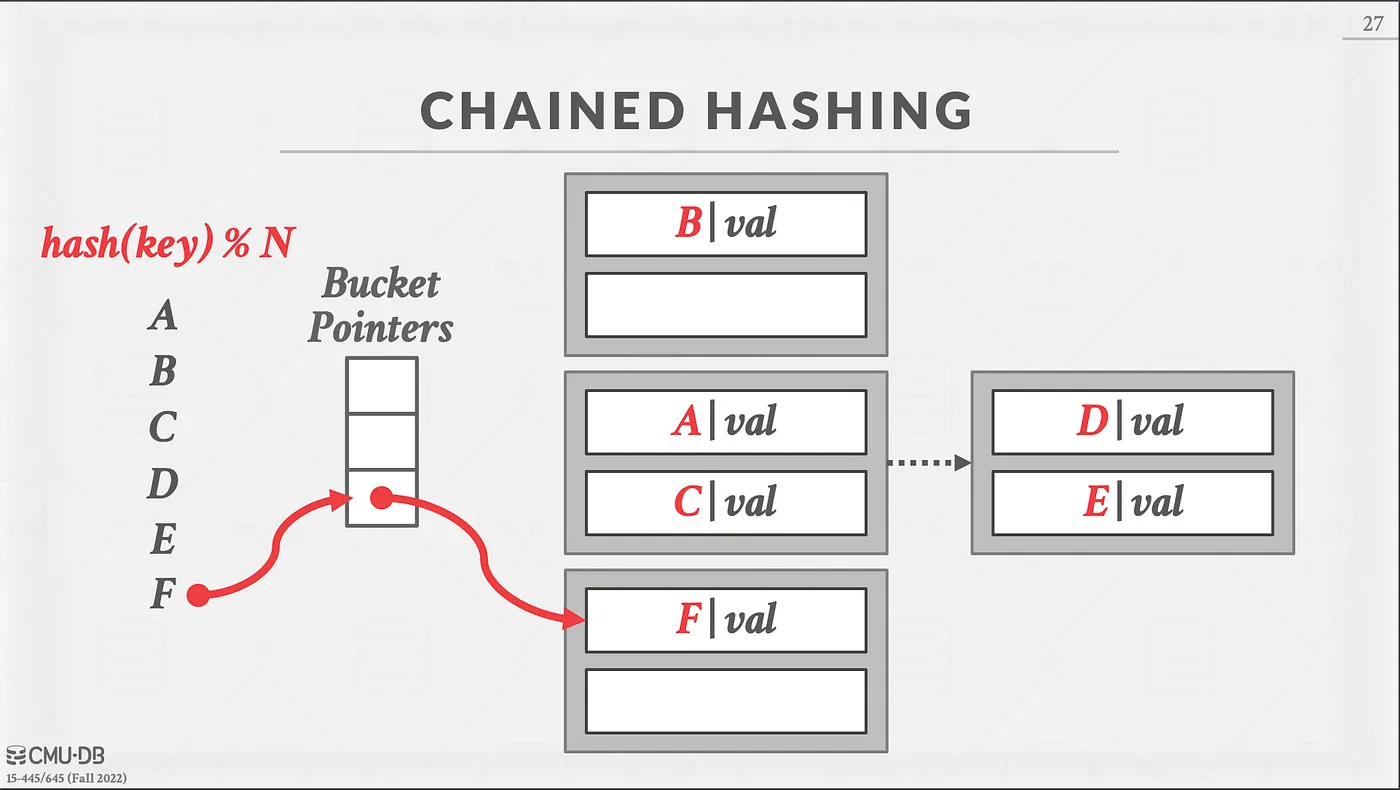
Insertion: Each key is hashed to a slot and every key is chained in a linked list. It could grow infinitely large but the searching complexity would be really bad. (Could be linear if all the keys are getting hashed to only a few buckets)
Finally, Extendible Hash Tables
Our project two assignment was to create an extendible hash table (with a slight twist). A general extendible hash table would utilize the global and local depths to determine the bucket where the key should land and local depths to check how many bucket slots would point to this bucket.
We follow this general rule during insertion:
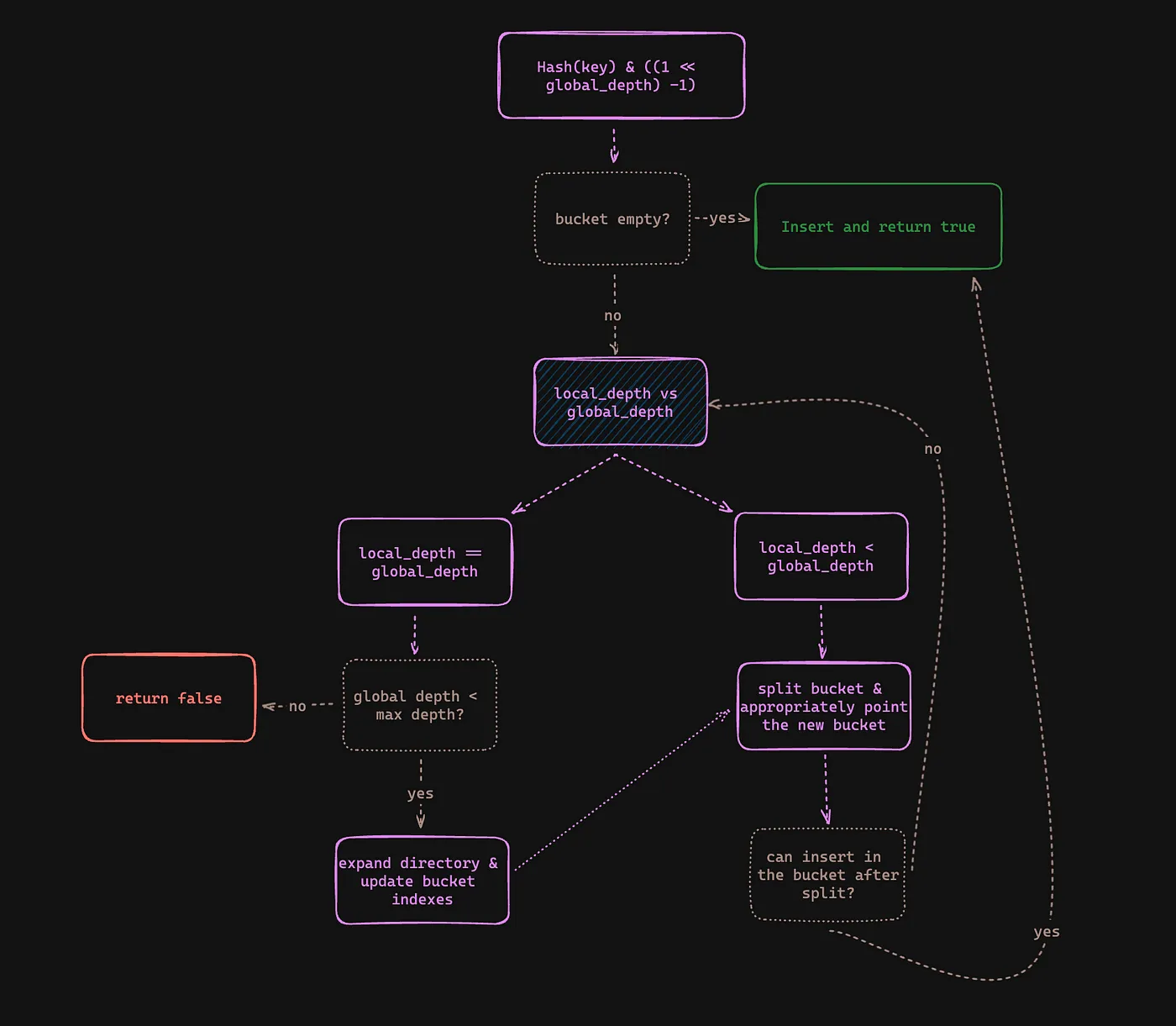
The above diagram’s slightly complicated ya? I agree, let me help and explain the overall idea. When you are inserting a key, you’d first check if there’s an appropriate empty bucket where the table could keep the key. If there’s some space, just push the key and forget.
If there’s no space though, you’d want to either expand the bucket or expand the table and make some space, for that to happen, you’ll
- First, verify if the bucket you want to push the key in has local_depth < global_depth. If that’s the case, you can just split the bucket in two and insert the new key accordingly.
- Second, if the
local_depth==global_depthyou would want to expand the directory by incrementing the global depth.
Let’s list down the type of fundamental database pages involved one by one and later on dry-run with an example.
Header Page
A single header page will have multiple directory pages. You can route the hashed keys according to the most significant bits (I will show that in the dry run) to a particular directory page. You could imagine this as a phone book of directories.
Directory Page
A single directory page will contain multiple buckets and each directory page will have the concept of
- Maximum depth: The maximum size a directory can expand to
- Global depth: The current depth of the directory. A directory can support a maximum of
1<<global_depthbuckets.
You’ll route the hashed keys to different buckets according to the least significant bits. (again, will show an example!)
Bucket Page
The bucket page will contain the key-value pairs. Each bucket will have:
- Maximum size: Total number of keys allowed.
- Local depth: This local depth is used to determine whether a key is supposed to stay in this bucket or not during bucket split/merge. In a directory,
exp(2, global_depth-local_depth)slots will be pointing to this bucket btw!
It’s also used to check during a bucket split, whether the keys that are present should stay or be migrated to a new bucket.
Example
Now, let’s consider the following scenario, We have the hashtable configuration as:
- header_depth = 1
- maximum_global_depth = 3
- maximum_bucket_size = 2
The keys and values will be uint32 and for demo’s sake, let’s assume our hash function is Hash(x) = x (I know, pretty catastrophic 😅)
Now, in this hashtable, let’s perform the following operations.
Operation 1 — Insert <23, 23>
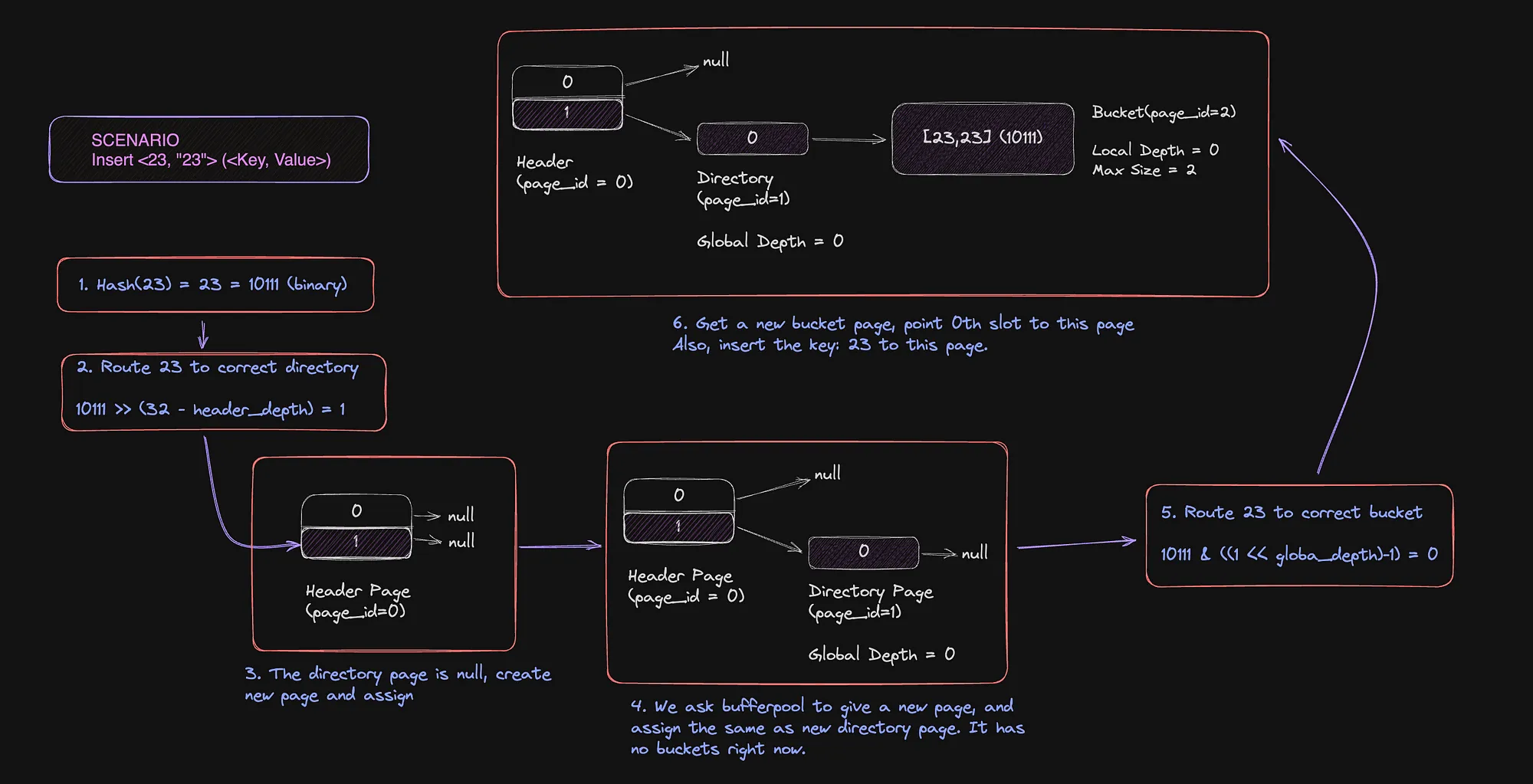
Two salient features I’ll ask you to focus on are the following steps:
- Step 2: When we are routing the key to the correct directory, we use the most significant bits of the hash to the resolution of the required bits, hence only the bold bits were required in directory routing bit: 10111,
- Step 5: Routing to the correct bucket, we use the least significant bits and the global depth. Well, right now the global depth of the directory is 0 so everything goes to the single slot!
Operation 2- Insert <7,7>
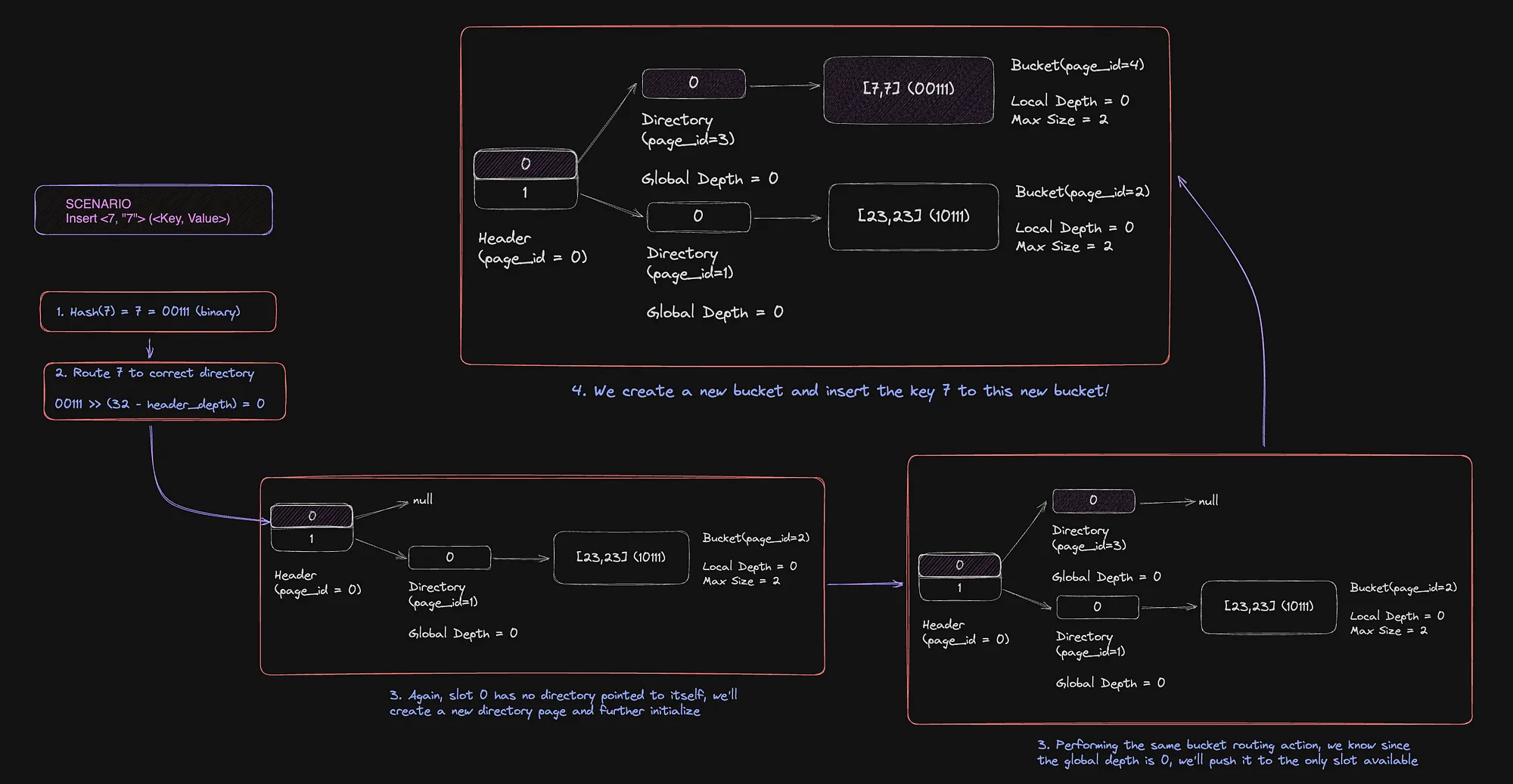
The only thing different from the last example is that it got routed to the 0th header slot rather than the 1th! Else, it’s business as usual.
Operation 3: Inserting <19, 19>
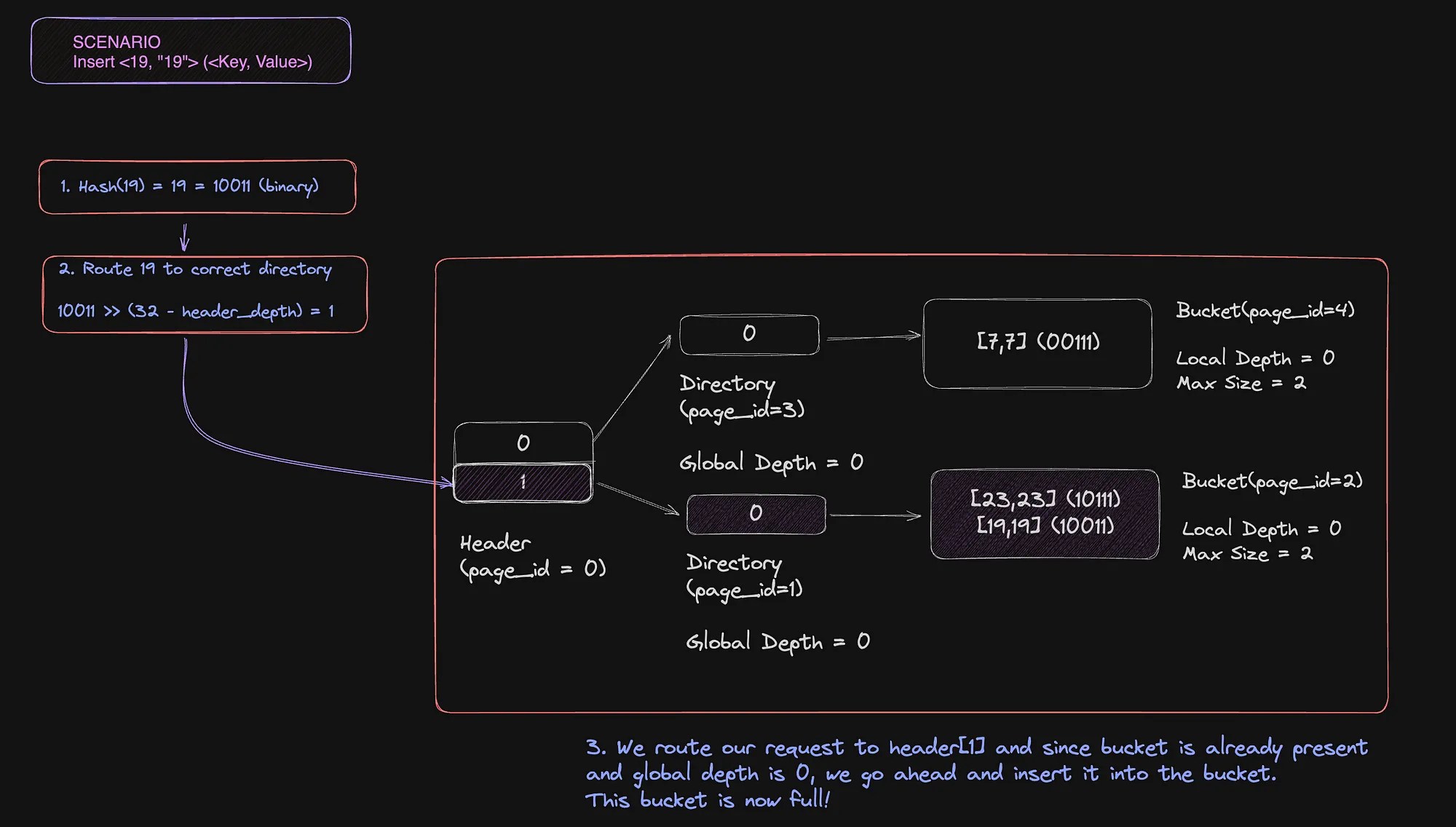
yes yes yes, I cut a few corners in this step but it’s pretty self-explanatory! We routed the request to the directory at header[1] and the only bucket present in the bucket following the old rules.
Operation 4: Inserting <20, 20>
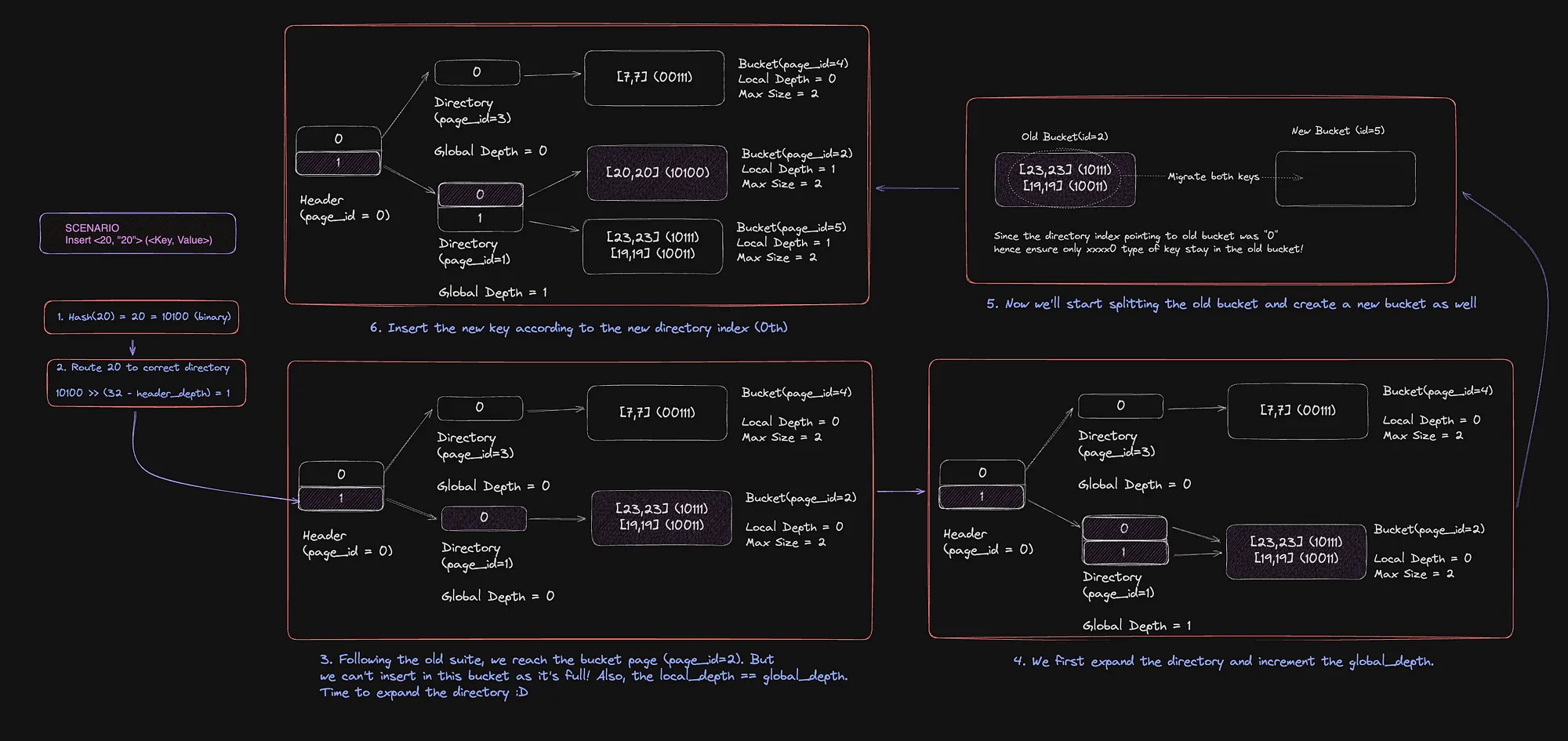
Now this is where things get interesting… 😋
You can’t insert the new key in the old bucket because it’s full, this is where the extensibility of this hash table comes in handy!
Since local_depth == global_depth && lobal_depth++ < maximum_global_depth , we have to expand this directory. During expansion, we create a new 1th index which is initially not pointed to anything, How do we figure out where should this new slot point to? I used the below-mentioned hacky algorithm to figure it out. (Kindly note, this ain’t the most elegant algorithm around to tackle this problem btw).
void ExtendibleHTableDirectoryPage::IncrGlobalDepth() {
LOG_DEBUG("----Increasing global depth-----");
// assert(global_depth_+1 <= max_depth_);
global_depth_++;
for (int i = 0; i < (1 << global_depth_); i++) {
if (bucket_page_ids_[i] == INVALID_PAGE_ID) {
// 0XXXX or 1XXXX needs to point to same bucket as --> XXXX
if (i == 0 || i == 1) {
LOG_DEBUG("Found invalid page id at %u, pointing it to %u's data", i, i ^ 1);
bucket_page_ids_[i] = bucket_page_ids_[i ^ 1];
local_depths_[i] = local_depths_[i ^ 1];
} else {
int right_shift_mask;
if (global_depth_ == 1) {
right_shift_mask = (1 << global_depth_) - 1;
} else {
right_shift_mask = (1 << (global_depth_ - 1)) - 1;
}
LOG_DEBUG("Found invalid page id at %u, pointing it to %u's data", i, i & right_shift_mask);
bucket_page_ids_[i] = bucket_page_ids_[i & right_shift_mask];
local_depths_[i] = local_depths_[i & right_shift_mask];
}
}
}
}Once the directory expansion is taken care of, we start the second task, actually splitting the older bucket and migrating keys accordingly.
Since directory[0] = old_bucket , we’ll ensure the following:
- The new bucket is accessible by the appropriate index in the directory.
- The keys present in the old bucket should stay if they satisfy the
key &((1 << local_depth)-1)
Conclusion
Kindly note that this is just a dummy run about insertions in extendible hash tables. The Get and Remove operations will follow similar suites.
There are many more internal operations required in the project, which were not covered in this blog, to name a couple:
- Resize (merge) multiple buckets into one upon removal of enough keys and subsequently shrink the directory pages.
- To ensure concurrent access, you can apply appropriate read and write latches on the pages.
I hope I could give you guys a gist of the beauty of an extendable hashtable index in terms of dynamic reallocation. To understand more, I’d recommend you to watch this lecture by Mr. Pavlo.
PS: I will update this post further as I progress with the above-mentioned requirements :)
